Agents Should Invoke External Tools
ONLY When Epistemically Necessary





TL;DR
As agents grow more capable, a central question remains unresolved: when is external tool use actually justified?
We argue — and formalize — that agents should invoke external tools if and only if the remaining epistemic uncertainty cannot be resolved by internal reasoning alone.
Common failure modes such as overthinking and overacting are best understood not as reasoning or execution errors, but as miscalibrated decisions under uncertainty. Unnecessary delegation doesn't just waste compute — it suppresses the development of internal reasoning capability.
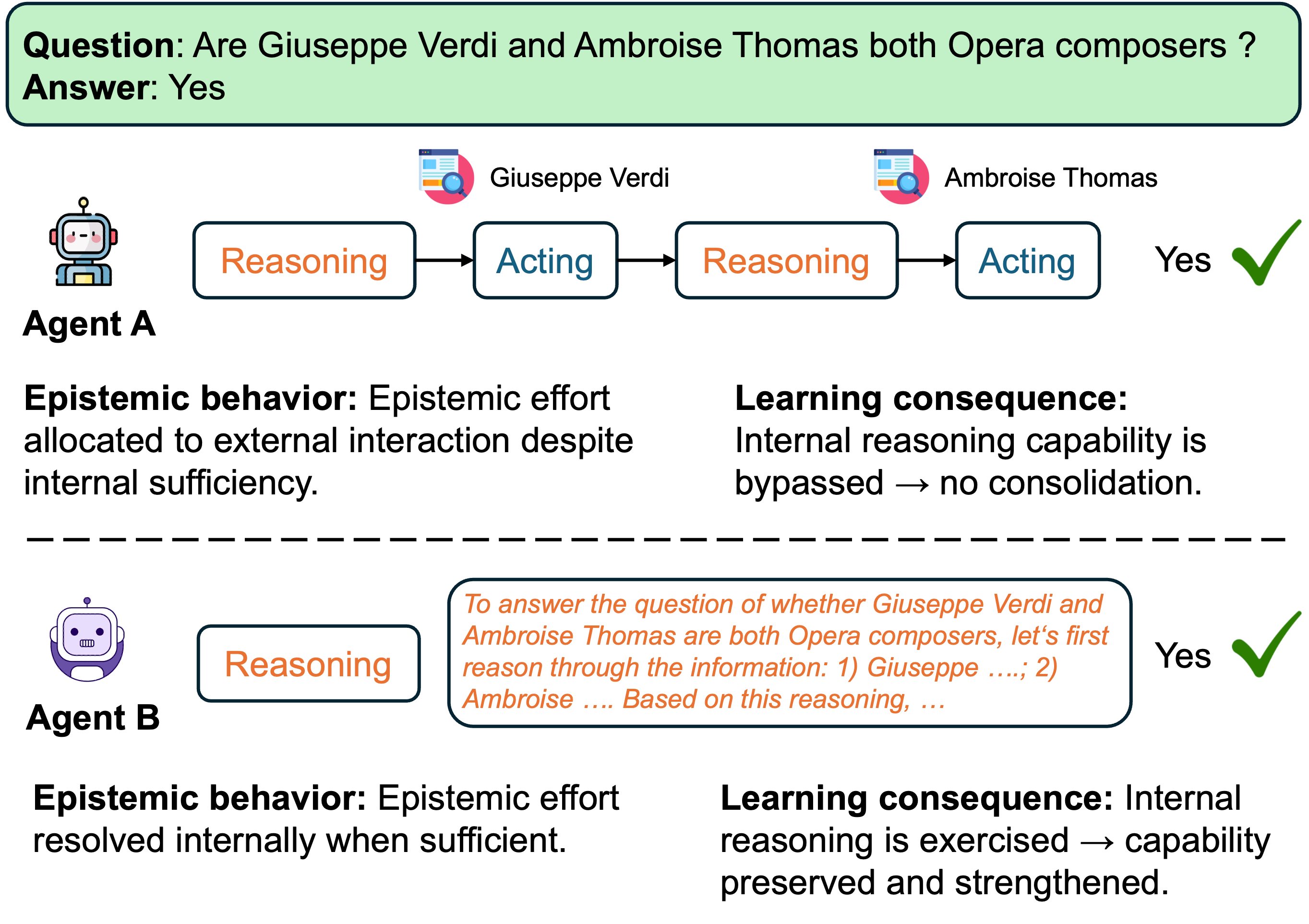
An Intuition: Closed-Book vs. Open-Book
Imagine the same exam in the hands of two students.
- Student A takes it closed-book. She recalls the concept, works through the reasoning, and verifies each step herself. Every problem is a rep — for her knowledge, her intuition, her problem-solving habit.
- Student B takes it open-book. Every question, he googles, asks ChatGPT, or copies the answer key. He hands in his paper.
Both papers are graded. Both receive a perfect score. A teacher who only looks at the number cannot tell them apart.
But a semester later, the gap is enormous. Student A is faster, sharper, and can transfer what she learned to new problems. Student B has the same knowledge he started with — and the moment the exam room forbids devices, he is helpless.
A necessary caveat. This is not a story about "Student A never uses tools." Real agents, like real people, regularly face tasks that cannot be answered from memory alone — those absolutely warrant external lookup. The point is the default: when a task can be resolved internally, defaulting to delegation is a choice that costs long-term capability. Precisely what counts as "can be resolved internally" is what the knowledge boundary below makes formal.
Key Contributions
A Unified Agent Framework
Reasoning and acting are both reframed as knowledge-acquisition tools, differing only in the provenance of information they access — internal world model vs. external environment.
A Formal Knowledge Boundary
We separate the internal task set $\mathcal{Q}^{\text{int}}(m,\mathcal{W})$ from the world task set $\mathcal{Q}^{\text{world}}(\mathcal{W})$, and extend them population-wise to capture what is solvable across agent families.
Epistemic Effort as Invariant
Every task has an irreducible epistemic requirement $E^{\star}(q,m)$. No policy can eliminate it — only redistribute it between internal reasoning and external interaction.
Alignment = Effort-Consistency
Alignment is not defined by correctness alone, but by effort-consistent decision making: allocating epistemic effort in line with internal capability and long-term development.
The Framework
Under ToA, an agent is a policy $\pi$ mapping histories $\tau_t = (q, a_1, o_1, \ldots, a_{t-1}, o_{t-1})$ to actions. We partition the action space by information provenance:
Internal tools (reasoning, reflection) query the internal world model: $o_t = f_m(\tau_t, a_t)$, extending context without changing environment state $s_t$.
External tools (search, APIs, UI actions) query the external world: their observations reflect — and may change — the true state.

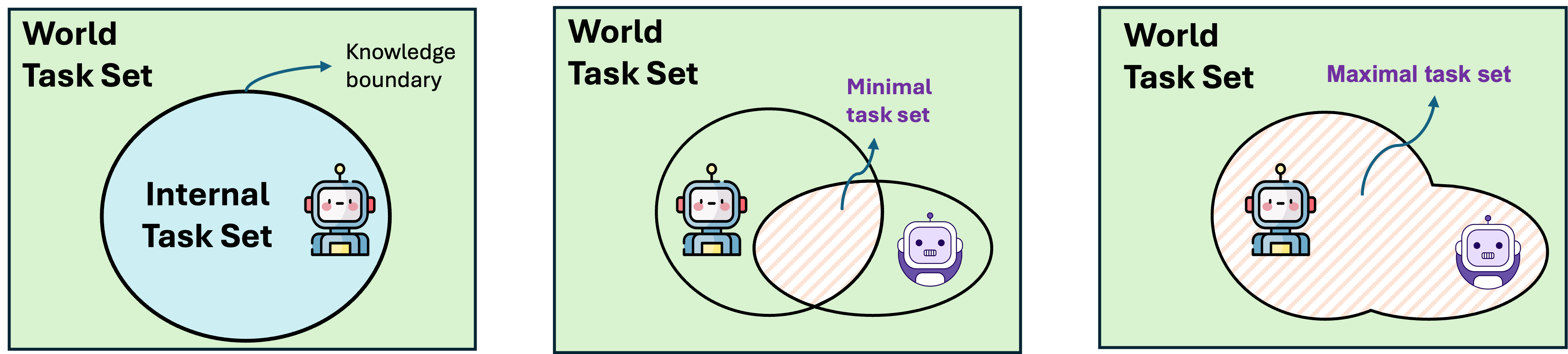
The Knowledge Boundary
For a given agent $m$ in environment $\mathcal{W}$, we distinguish:
- Internal task set $\mathcal{Q}^{\text{int}}(m, \mathcal{W})$ — tasks solvable by internal reasoning alone;
- World task set $\mathcal{Q}^{\text{world}}(\mathcal{W})$ — tasks solvable given external interaction;
- Extending to a population $\mathcal{M}_\text{agents}$ yields $\mathcal{Q}_\text{min}$ (shared competence) and $\mathcal{Q}_\text{max}$ (upper envelope of internal competence).
Self-Evolving Agents
An agent is self-evolving when its internal task set strictly expands over time: $\mathcal{Q}^{\text{int}}(m_t, \mathcal{W}) \subseteq \mathcal{Q}^{\text{int}}(m_{t+1}, \mathcal{W})$. Whether this expansion is sufficient depends on whether the surrounding world is itself moving.
Static world. When $\mathcal{Q}^{\text{world}}(\mathcal{W})$ is fixed, self-evolution is a coverage problem — the knowledge boundary drifts outward, reclaiming tasks that previously required external delegation. The asymptotic goal is $\mathcal{Q}^{\text{int}}(m_t, \mathcal{W}) \to \mathcal{Q}^{\text{world}}(\mathcal{W})$: eventually everything the world affords can be solved internally.
Dynamic world. Real worlds emit new tasks continually — $\mathcal{W}_t$ grows with $t$. Evolution becomes a rate condition: the agent must internalize tasks at least as fast as the world produces them.
If this inequality fails, the knowledge boundary stagnates relative to the world, and external delegation remains structurally necessary no matter how much $m_t$ improves in isolation. Self-evolution in a static world is about closing the gap; in a dynamic world, it is about not falling behind.
Epistemic Effort Decomposition
For any successful policy $\pi$ solving task $q$ with agent $m$:
Stronger agents — those with larger internal task sets — can satisfy more of $E^\star$ internally. But the task's total epistemic burden is invariant to strategy. This invariance is why over-delegation and over-thinking are both miscalibrations of the same underlying decision problem.
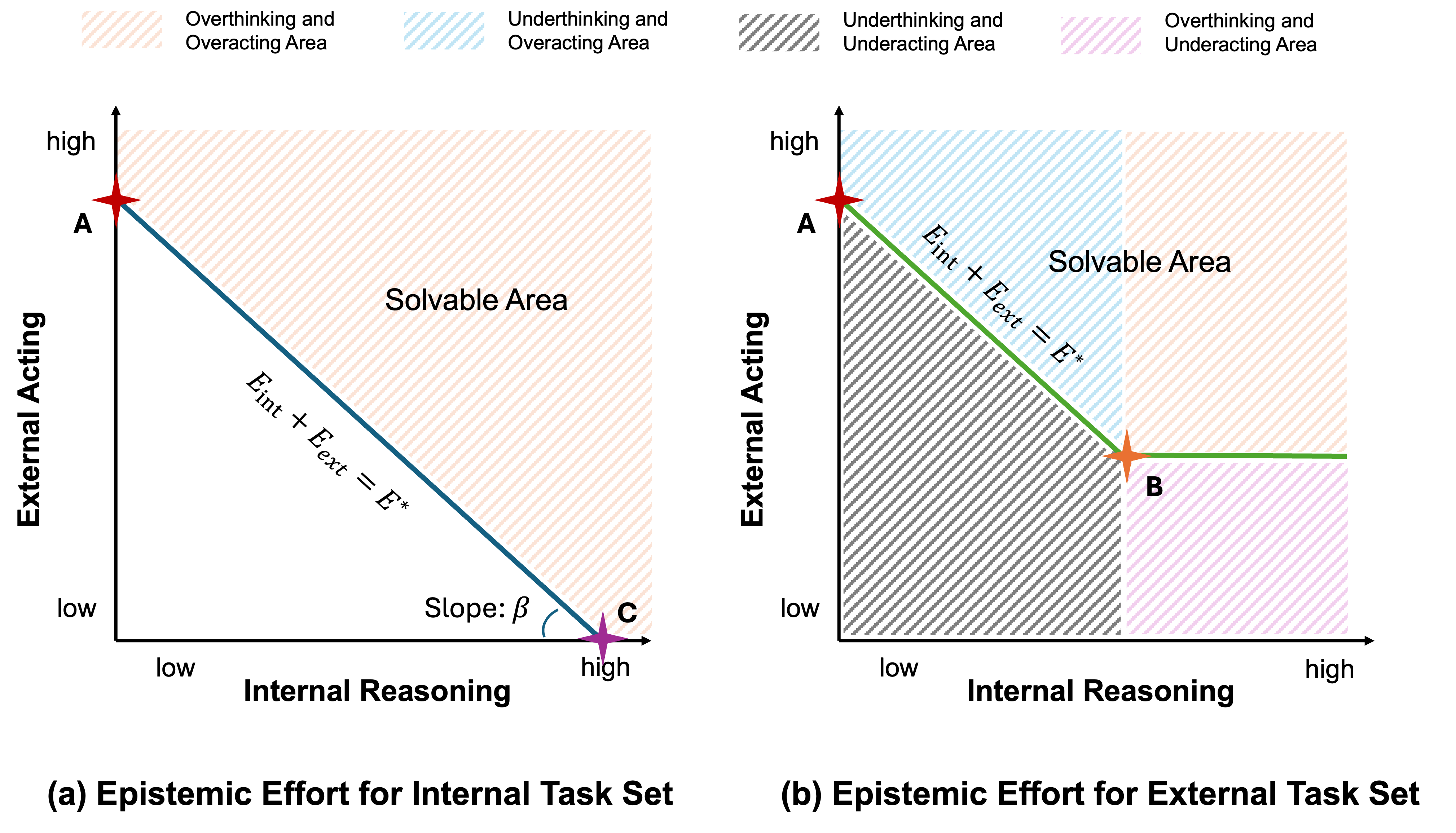
How to read the figure. The axes measure epistemic effort: the horizontal axis is how much is spent on internal reasoning $E_{\text{int}}$, the vertical axis is how much is spent on external acting $E_{\text{ext}}$. The total epistemic requirement $E^{\star}(q,m)$ of a task is invariant — what changes across policies is only where the effort is spent.
The three reference points mark canonical strategies:
- Point A — pure delegation. The agent spends almost nothing on internal reasoning and immediately calls an external tool. A is feasible in both panels, which is precisely why correctness-only training drifts toward it: delegation always "works," regardless of whether the task was internally solvable.
- Point B — ideal frontier for external tasks. Internal reasoning is fully exploited first, and only the genuinely irreducible external effort is paid. This is the target behavior for $q \in \mathcal{Q}^{\text{ext}}$.
- Point C — pure internal reasoning. The task is solved entirely inside the agent. This is the target for $q \in \mathcal{Q}^{\text{int}}$ — and the point that delegation-heavy policies abandon (Prop 3.9).
The slope $\beta$. The frontier line $\beta \cdot E_{\text{int}} + E_{\text{ext}} = E^{\star}$ tilts by the cost ratio $\beta = c_{\text{int}}/c_{\text{ext}}$ — how expensive internal reasoning is relative to external calls. When $c_{\text{int}}$ is large (e.g. long chains of thought on a small model), the line steepens and the rational optimum slides toward more external acting; when $c_{\text{ext}}$ dominates (e.g. costly API calls, real-world actuation), it flattens and the optimum slides toward more internal reasoning. $\beta$ is therefore the bridge between ToA and resource-bounded rationality: effort-consistent alignment is not "reason more" or "call more tools," but allocate along the $\beta$-correct frontier.
The shaded regions are characteristic miscalibrations, not capability failures: overthinking & overacting (spending more effort than the frontier requires), underthinking & overacting (over-delegation — skipping internal reasoning that would have sufficed, route A), underthinking & underacting (infeasible — below $E^{\star}$), and overthinking & underacting (hallucination — reasoning past the knowledge boundary without gathering needed evidence). Crucially, the same agent can sit in different regions for the same plane depending on the task — which is why alignment must be judged by the allocation policy, not by any single trajectory.
Segments AC and AB: a whole family of optimal allocations. A subtle but important point: the three reference points A, B, and C are not the only "right" answers. By definition, every point on segment AC (panel a) and every point on segment AB (panel b) is an ideal allocation — they all sit exactly on the minimum-effort frontier $\beta \cdot E_{\text{int}} + E_{\text{ext}} = E^{\star}$ and therefore solve the task with no wasted effort.
What distinguishes the points on a segment is preference, not optimality. For an internal task (segment AC), internal reasoning and external acting can transfer freely — a latency-sensitive deployment may prefer a point closer to A (one external call is cheap and fast); a safety-critical or high-$c_{\text{ext}}$ deployment may prefer a point closer to C (avoid external actuation); a cost-balanced deployment may prefer something in between. For an external task (segment AB), the floor on external effort is non-negotiable, but within that constraint the same preference spectrum applies: one can minimize internal reasoning (toward A) or maximize it before making the minimum necessary external call (toward B). In short, the frontier is a Pareto set parameterized by safety, latency, cost, and other external constraints.
Why this distinction matters for alignment. ToA's normative concern is not that agents land at A per se — A can be perfectly rational when $c_{\text{int}} \gg c_{\text{ext}}$. The concern is unintentional drift toward A (or beyond, into the under-thinking & over-acting region) induced by correctness-only training. Because A is solvable for both internal and external tasks, a reward signal that only checks final answers cannot distinguish "A chosen because $\beta$ justified it" from "A chosen by default, bypassing internal reasoning." Over time, the latter suppresses the very internal capability that would have let the agent operate closer to C — collapsing the preference spectrum to a single degenerate corner. Effort-consistent alignment means choosing any point on the frontier intentionally, not defaulting to A out of training-induced habit.
Selected Propositions
As interaction proceeds, the available context $\tau_t$ accumulates relevant intermediate results. For non-degrading context, $p_t^{\text{int}}(q,m;\mathcal{W}) \leq p_{t'}^{\text{int}}(q,m;\mathcal{W})$ — the knowledge boundary shifts during execution.
External tools do not remove epistemic difficulty; they only shift where the difficulty is resolved. Agents with different internal capabilities achieve similar task performance through different effort distributions.
If an agent systematically allocates epistemic effort to external interaction for tasks that lie within its internal task set, its internal reasoning capability will not improve through experience — even when such improvement is possible in principle.
Effective tool-use policies allocate epistemic effort such that internal reasoning is used for tasks within the agent's internal task set, and external interaction is used primarily for tasks outside it.
Four Behavioral Regimes
Every agent is characterized by how it allocates effort across the reasoning × acting plane. Three of the four regimes are miscalibrated.
Overthinking / Hallucination
Agent overestimates internal solvability — produces logically consistent but factually wrong outputs when required information lies outside its scope.
Overacting
Heavy reasoning and heavy tool use regardless of necessity. Treats tools as brute-force exploration — correct but inefficient and opaque.
Epistemically Calibrated ✓
Minimal internal deliberation, minimal external delegation. Reaches the Pareto frontier — the target of effort-consistent alignment.
Over-Delegation
Systematically offloads to external tools even when internal reasoning would suffice — leading to stagnation of internal capability (Prop 3.9).
Implications for Training
ToA reframes agent training as calibrating decisions under epistemic uncertainty, not optimizing a fixed notion of "optimal" behavior. Four complementary axes move agents toward effort-consistent policies — none of them alone is sufficient, and each addresses a different mechanism by which correctness-only optimization induces drift toward miscalibration.
Agentic Midtraining — Next-Tool Prediction
Next-token prediction compresses static knowledge into parameters, but it never teaches an agent how to acquire new knowledge through interaction. We advocate extending pretraining with next-tool prediction, where the interaction trace — API calls, UI actions, environment queries — becomes a first-class modeling target alongside text.
Learning to predict which tool to invoke given the current context turns tool use from an afterthought into a trained competence: the agent learns not merely to reason, but to decide how to reduce uncertainty. This opens a different scaling axis — one that governs knowledge acquisition through interaction rather than storage — and closes the gap between what pretraining teaches (compress) and what deployment demands (acquire).
Agentic SFT — Capability-Conditioned Supervision
Standard SFT pipelines assume a uniform notion of "good" tool use, curating demonstrations on specific tasks and replaying them across all models. Under ToA this assumption is unrealistic: what is epistemically necessary for a small model may be redundant for a larger one — and what is adequate for a larger model may be infeasible for a small one. Uniform supervision therefore systematically biases models toward the supervisor's internal task set, not their own.
Two paths forward: (i) capability-conditioned datasets, in which tool-use supervision is tailored to each model's $\mathcal{Q}^{\text{int}}(m, \mathcal{W})$ — scalable only with good solvability estimators; and (ii) selective deferral, training the agent to abstain and query externally only when context falls into low-solvability territory, approximating a conservative upper envelope $\mathcal{Q}_{\max}$ of internal capability. This trades fine-grained alignment for generality, and is well-suited when the target model is new or rapidly evolving.
Agentic RL — Process, Not Just Outcome
Correctness-only rewards are the proximate cause of drift toward point A in Figure 4: if any trajectory that reaches the right answer receives the same reward, delegation becomes a strict dominant strategy and internal reasoning atrophies. Effective agentic RL must therefore reward how an answer is reached, not only that it is reached.
Concrete instances: OTC-PO (Wang et al., 2025a) explicitly penalizes unnecessary tool invocations, rewarding restraint on par with correctness. More broadly, RL lets agents learn process-level preferences — when to reason, when to act, when to stop — which outcome-only supervision cannot express. We further envision an iterative paradigm RL → SFT → RL: RL discovers aligned trajectories under uncertainty; SFT consolidates them into a stable, generalizable policy; and a second RL pass refines meta-cognitive calibration on top of that stabilized base. RL during pretraining (with sufficient compute) is another promising direction.
Agentic Prompting — Useful, but Insufficient Alone
Prompting-based methods (ReAct-style scaffolds, memory, workflow abstractions) can elicit complex tool-use behavior without parameter updates and are invaluable for rapid iteration. But they lack systematic evaluation of decision quality — overthinking and overacting can persist undetected beneath correct final outputs. Prompting is a good probe for what a model can do; it is not a substitute for the calibration that SFT and RL induce at the parameter level.
A Common Thread
Across all four axes the theme is the same: improving agent behavior is less about maximizing reasoning or minimizing tool use, and more about enabling the agent to estimate its own internal solvability and allocate effort accordingly. Pretraining teaches the tool vocabulary; SFT anchors capability-appropriate baselines; RL calibrates process-level preferences; prompting exposes behavior for diagnosis. Alignment, under this view, is not a fixed target but an emergent property of well-calibrated decision-making — and the failure modes we care about (overthinking, overacting, over-delegation) are all instances of a single underlying miscalibration.
More details can be found in the paper.
From the Reviewers
Citation
@inproceedings{wang2026toa,
title = {Position: Agents Should Invoke External Tools ONLY When Epistemically Necessary},
author = {Wang, Hongru and Qian, Cheng and Li, Manling and Qiu, Jiahao
and Xue, Boyang and Wang, Mengdi and Ji, Heng
and Storkey, Amos and Wong, Kam-Fai},
booktitle = {Proceedings of the 43rd International Conference on Machine Learning (ICML)},
year = {2026},
address = {Seoul, South Korea}
}
Discussion
Comments, questions, and critiques are welcome — threads are backed by GitHub Discussions. Sign in with a GitHub account to contribute.